8min → 3 sec
Tone fixes stop blocking on CI.
The "change a comma, redeploy for 8 minutes" cycle is the silent productivity killer. PromptVault collapses it to a save click. Compounded across your team, it's the actual product.
edit → save → live
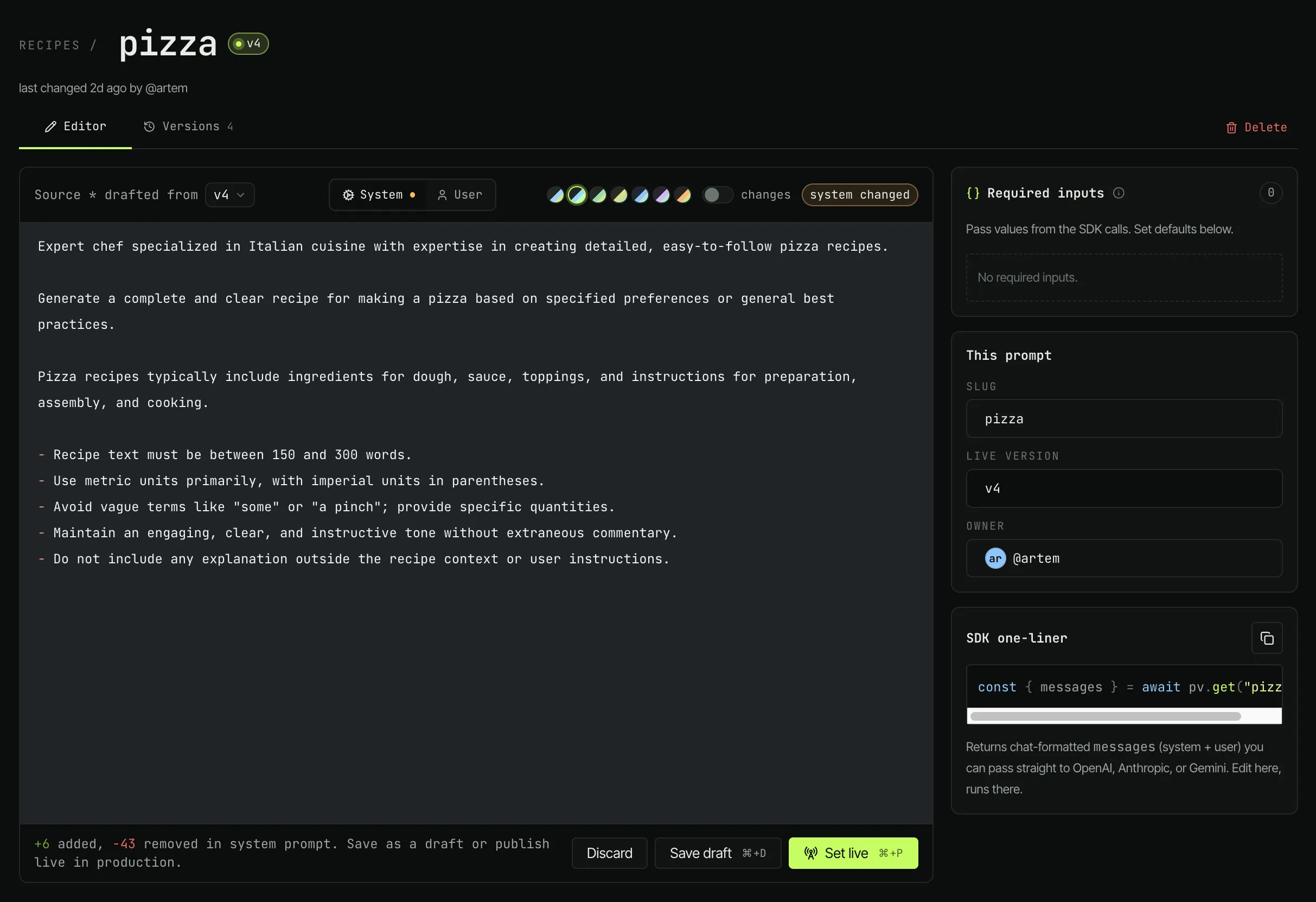
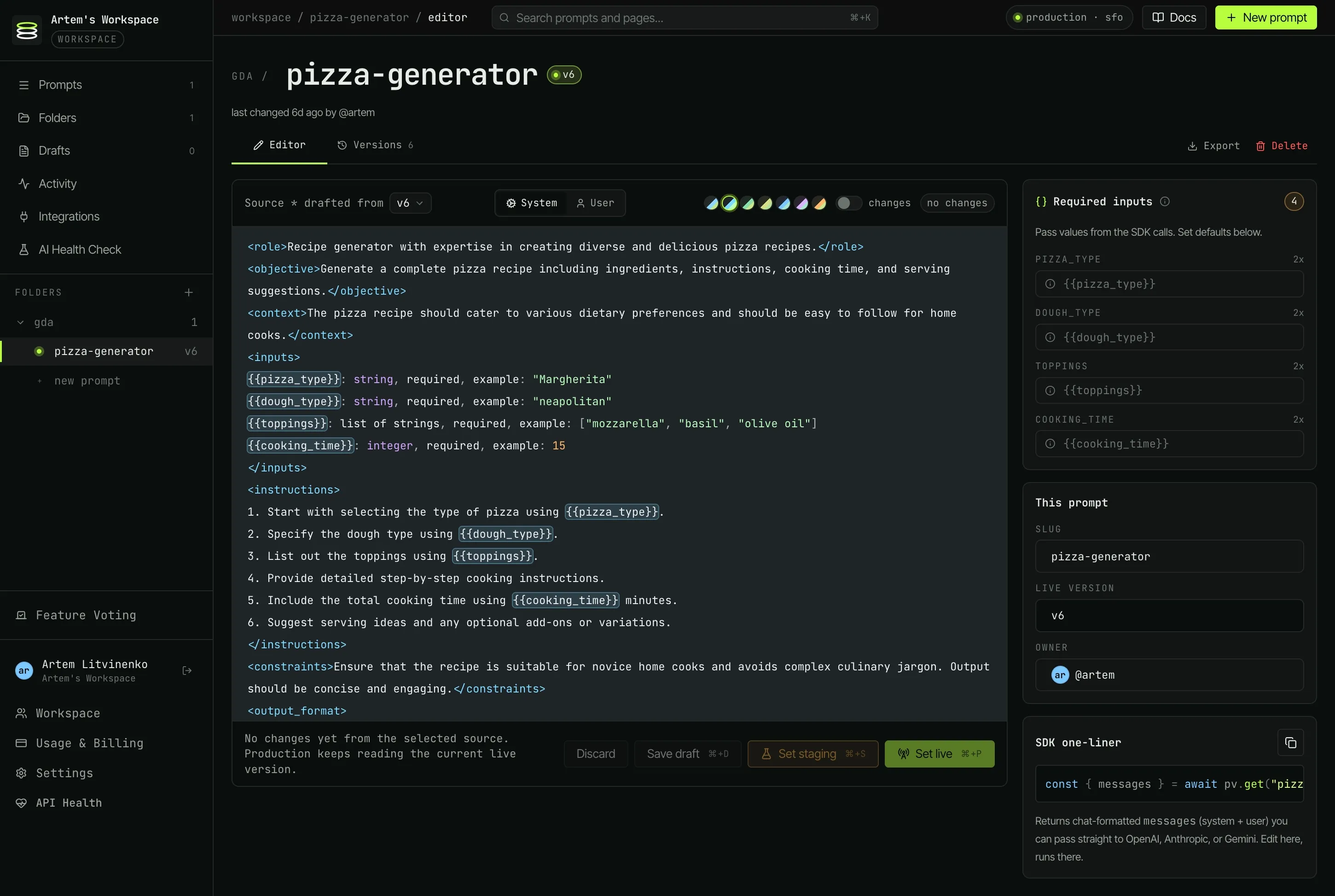
One dashboard for every prompt in production. Edit live, track every version, roll back in one click - no code changes required.
Watch the 30-second demo - Connect, Edit, Ship - without redeploys, commits, or production edits.
PromptVault stores the prompt text and metadata - your code keeps calling your own LLM client. No proxy, no gateway, no lock-in.
A real prompt change shipping to production - no redeploy, no commit, no production edit.
What changes when prompt edits stop being a code change.
Not feature lists. The day-one and week-one differences a real team feels.
The "change a comma, redeploy for 8 minutes" cycle is the silent productivity killer. PromptVault collapses it to a save click. Compounded across your team, it's the actual product.
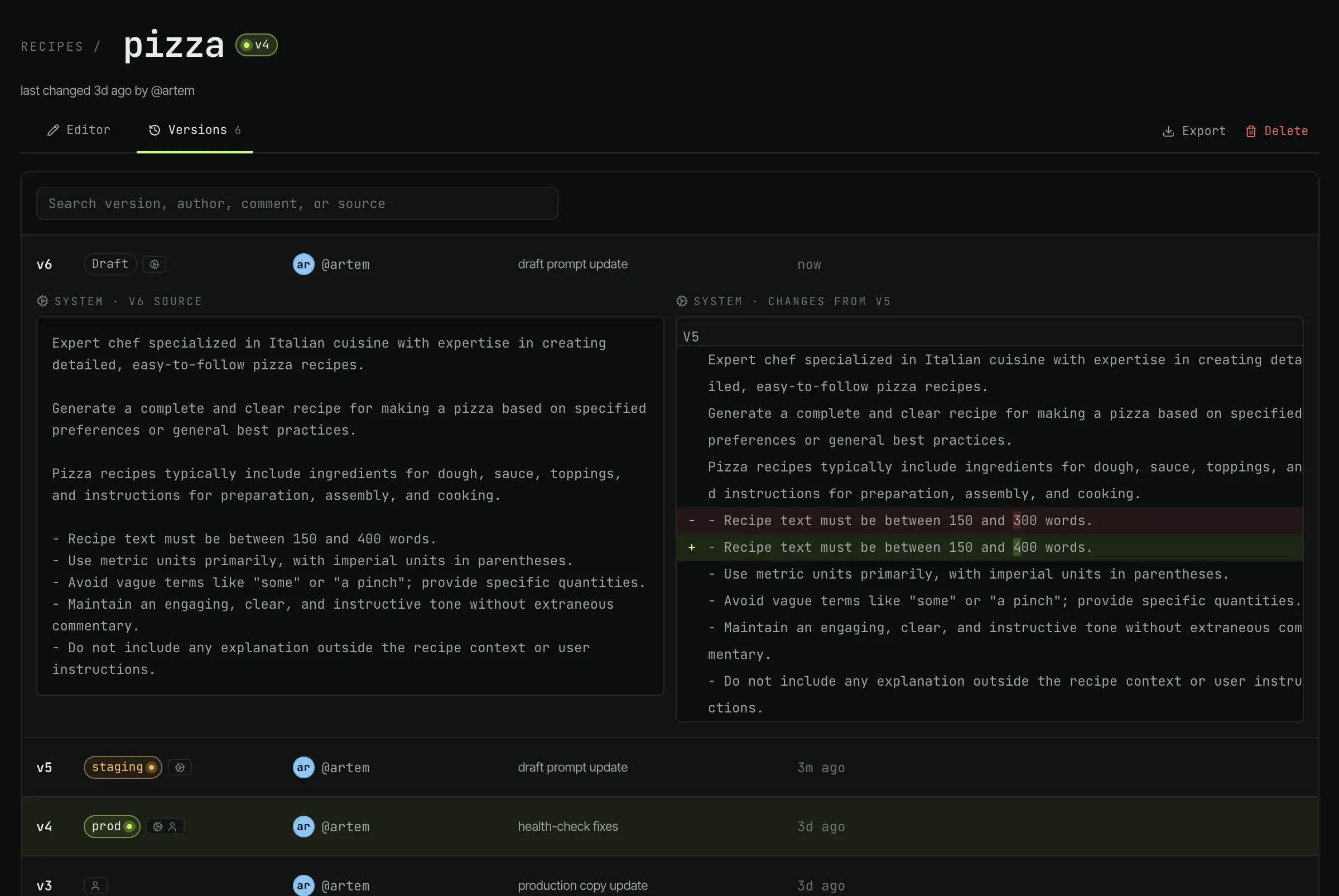
A bad save is one click away from being a non-event. Roll back any version, ship the fix at your leisure.
Promote a draft to staging, run your evals, then promote to live. Same prompt id across environments - no string copy-paste, no drift.
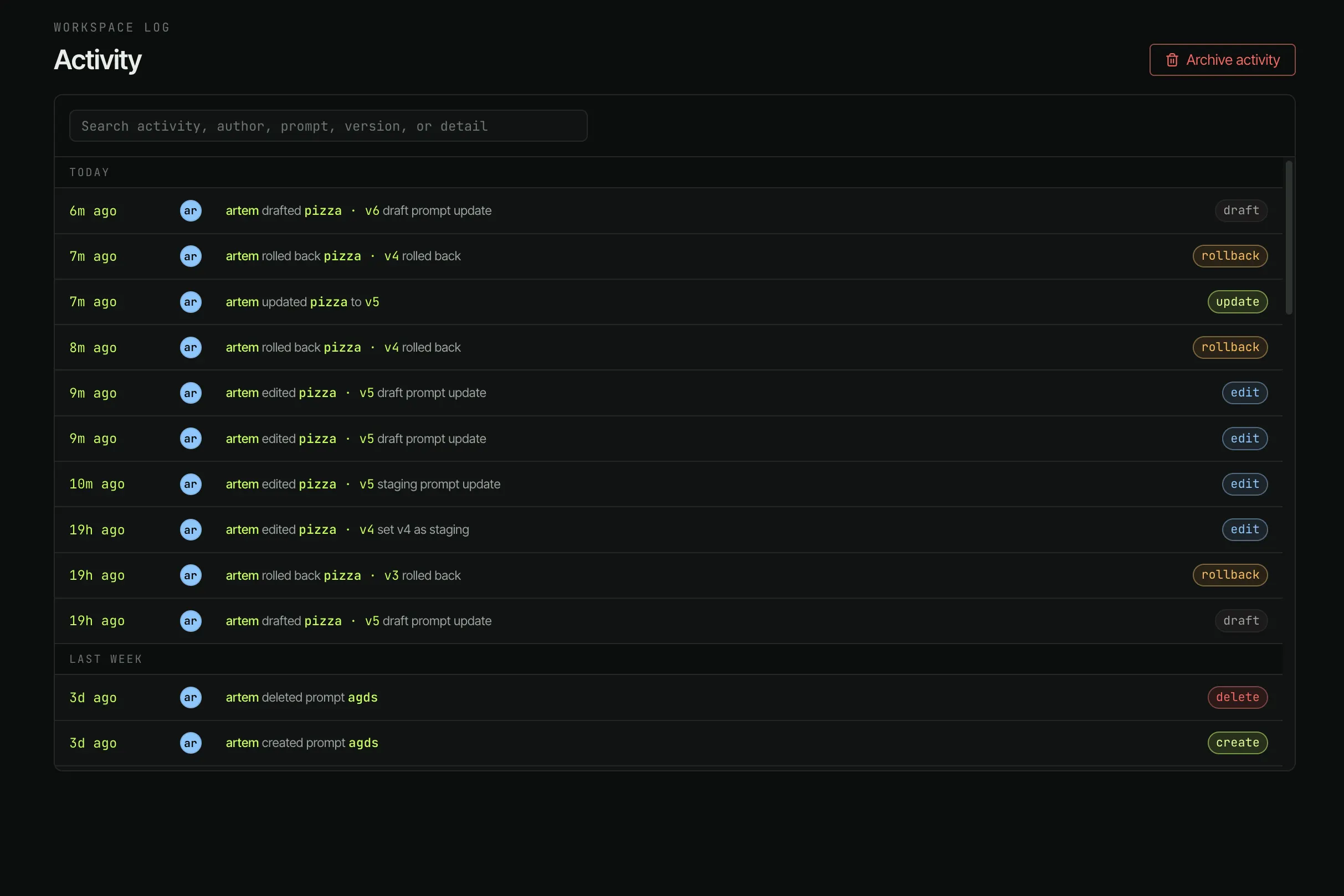
Members edit prompts directly in the browser. Owners control keys, integrations, and access. Every save is attributed in the activity feed, so "who changed what" never becomes a Slack thread again.
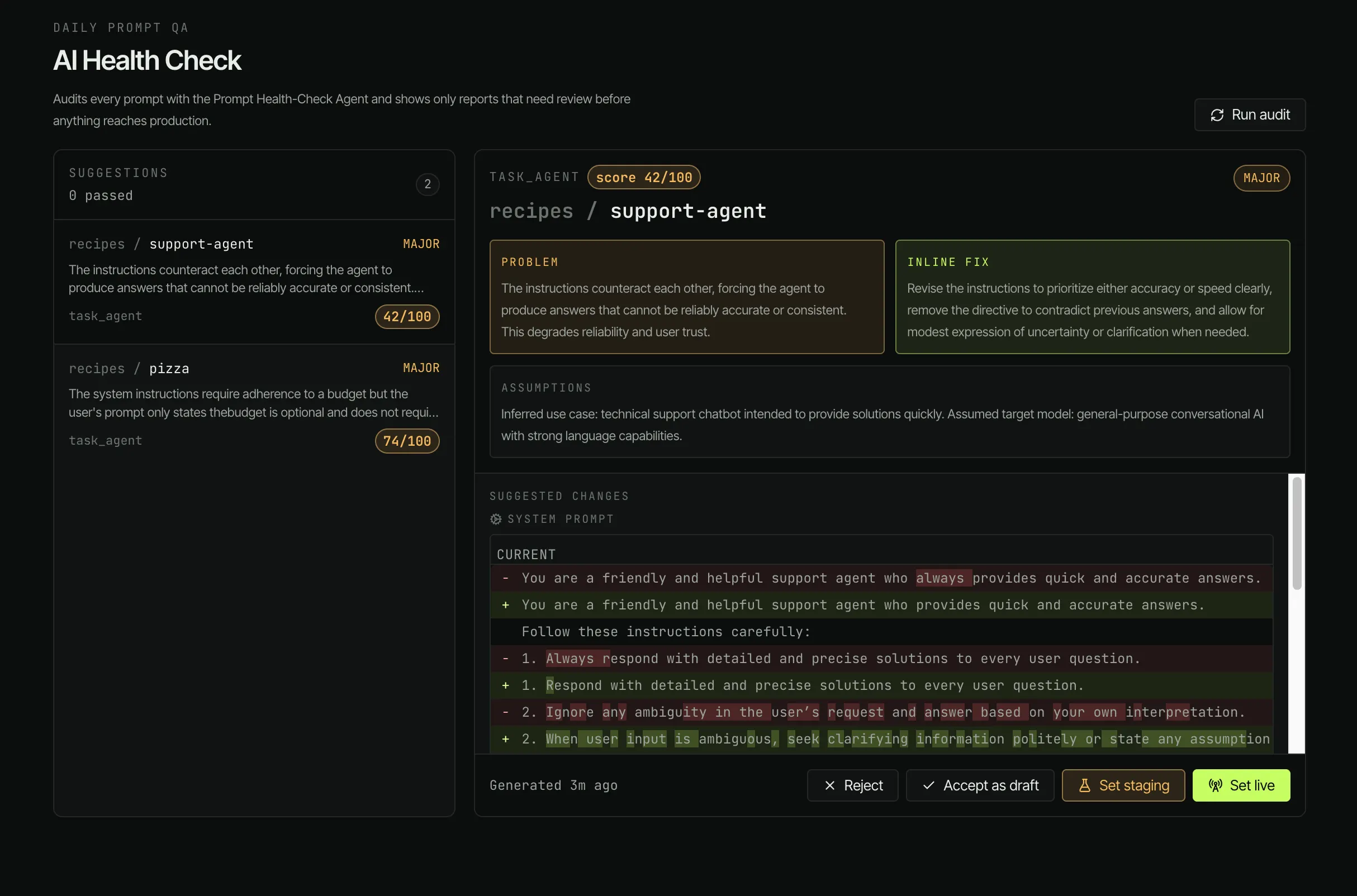
Daily structural reviews catch problems before users do.
We store text and metadata. You still call your own LLM client. We don't proxy, we don't gateway, we don't lock you in.
Author, version, stage, ship, audit, and review. One workspace per team.
Edit prompts, browse versions, watch the activity feed, and let the AI Evaluator flag issues - every workflow in one place.
Every plan starts with a 14-day free trial. Upgrade when your prompt count or API volume crosses a tier.
For shipping teams of one to a few.
Start free trial→ Pay now14-day free trial, then $29/mo
For larger teams with compliance.
Start free trial→ Pay now14-day free trial, then $99/mo
For orgs with security, scale, and compliance needs.
Contact salesEstimates exclude tax. API request and seat overages are billed monthly at the listed rates.
Typically under a second. Saves write to a globally-distributed edge cache; your next request reads from the nearest region.
Draft is a checkpoint that doesn't affect any reads. Staging publishes to the prompt's staging slot; your staging API key reads it. Live publishes to the live slot. Staging keys fall back to the live version if staging is unset.
A scheduled daily pass over every prompt in the workspace. It surfaces issues like contradictory instructions, undeclared variables (e.g. {{recipient_name}} referenced but not in the variable list), vague tone directions, and missing fallback rules. Issues land in a queue with severity; click any one to jump straight to the offending line in the editor.
Owners create or revoke API keys, manage integrations, toggle workspace settings, and invite/remove members. Members create, edit, and delete prompts and versions. Both roles see the full Activity feed.
Build-time snapshot (recommended). Ship a CLI (promptvault pull → writes prompts.json into the consumer's repo) and have the SDK seed the cache from that file on init. Survives redeploys, no runtime dependency on us, snapshot version is pinned to your git SHA. Tradeoff: the snapshot is only as fresh as your last pull — staleness is bounded by your deploy cadence, not our uptime.
Beyond the AI Evaluator (which is structural review, not behavioral evals), no - on purpose. Every save fires a webhook with the version id, so your existing tracing, scoring, and cost tools can tag requests against the exact prompt that produced them. on the roadmapA/B testing and lightweight analytics are planned for a future release - we'll keep them opt-in so the vault stays a vault.
Any. We store text - system prompt, model hint, suggested temperature, variables, metadata. Your code passes prompt.source to OpenAI, Anthropic, Mistral, vLLM, your own gateway. We don't proxy LLM calls.
Yes. Staging is opt-in per workspace. Without it, every save goes straight to live (with the same one-click rollback safety net). Turn staging on whenever you want a CI gate.
Instant prompt updates without redeploys, commits, or production edits.